Kurtosis
En théorie des probabilités et en statistique, le kurtosis (du nom féminin grec ancien κύρτωσις, « courbure »), aussi traduit par coefficient d’acuité[1], coefficient d’aplatissement et degré de voussure, est une mesure directe de l’acuité et une mesure indirecte de l'aplatissement de la distribution d’une variable aléatoire réelle. Il existe plusieurs mesures de l'acuité et le kurtosis correspond à la méthode de Pearson.
C’est le deuxième des paramètres de forme, avec le coefficient d'asymétrie (les paramètres fondés sur les moments d’ordre 5 et plus n’ont pas de nom propre).
Il mesure, abstraction faite de la dispersion (donnée par l’écart type), la répartition des masses de probabilité autour de leur centre, donné par l’espérance mathématique, c’est-à-dire, d’une certaine façon, leur concentration à proximité ou à distance du centre de probabilité.
Définitions
Kurtosis non normalisé (coefficient d’aplatissement)
Étant donné une variable aléatoire réelle d’espérance et d’écart type , on définit son kurtosis non normalisé comme le moment d’ordre quatre de la variable centrée réduite :



![{\displaystyle \beta _{2}=\mathbb {E} \left[\left({\frac {X-\mu }{\sigma }}\right)^{4}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4f85faccce3633a494ae3c73dead4d3efe3bb88c)
lorsque cette espérance existe. On a donc :

avec les moments centrés d’ordre .


Kurtosis normalisé (excès d’aplatissement)
Le kurtosis non normalisé étant défini en fonction de moments centrés, il est malaisé à manipuler lorsqu’il s’agit de calculer celui de la somme de variables indépendantes.
On définit ainsi le kurtosis normalisé en fonction de cumulants :

Sachant que et , on a alors[2]:



Propriétés
Dimension
Les moments centrés et cumulants ayant pour dimension celle de la variable élevée à la puissance , les kurtosis et sont des grandeurs adimensionnelles.



Plage de valeur
Soit la variable aléatoire réelle . Cette variable aléatoire a pour espérance et pour variance . Sachant que , on en déduit alors que :






Cette limite inférieure n’est atteinte que dans le cas où (à transformation affine près) la variable aléatoire X suit une loi de Bernoulli de paramètre (un seul tirage à pile ou face avec une pièce parfaitement équilibrée). Pour la loi normale, on a .


Le kurtosis n’a pas de limite supérieure.
Somme de réalisations indépendantes
Soient une variable aléatoire réelle et la somme de réalisations indépendantes de (exemple : la loi binomiale de paramètres et , somme de réalisations indépendantes de la loi de Bernoulli de paramètre ). Grâce à la propriété d’additivité des cumulants, on sait que , donc :





Typologie
Un coefficient d’aplatissement élevé indique que la distribution est plutôt pointue en sa moyenne, et a des queues de distribution épaisses (fat tails en anglais, fat tail au singulier). Cela se déduit en considérant la distribution définie plus haut, dont l’espérance vaut 1 et dont le moment centré d’ordre deux est le kurtosis non normalisé de . Comme son espérance est fixée, son moment d’ordre deux ne peut évoluer que par compensation : pour l’augmenter, il faut de l’inertie en position éloignée, contrebalancée par de l’inertie proche. En d’autres termes, on « pince » les flancs et les probabilités se déplacent par conséquent vers le centre et les extrémités.

Le terme d'« excès d’aplatissement », dérivé de kurtosis excess en anglais, utilisé pour le kurtosis normalisé peut être source d’ambiguïté. En effet, un excès d’aplatissement positif correspond à une distribution pointue et un excès d’aplatissement négatif à une distribution aplatie (on s’attendrait à l’inverse).
Distribution mésokurtique
Si , on parle de distribution mésokurtique (ou mésocurtique). La loi normale est un cas particulier de distribution mésokurtique pour laquelle le coefficient de dissymétrie vaut 0.

Distribution leptokurtique
Si , on parle de distribution leptokurtique (ou leptocurtique). La notion de leptokurticité est très utilisée dans le milieu de la finance de marché, les échantillons ayant des extrémités plus épaisses que la normale, impliquant des valeurs anormales plus fréquentes[3].

Distribution platikurtique
Si , on parle de distribution platykurtique (ou platycurtique, platikurtique, platicurtique). Pour une même variance, la distribution est relativement « aplatie », son centre et ses queues étant appauvries au profit des flancs.

Exemples de kurtosis pour quelques distributions absolument continues
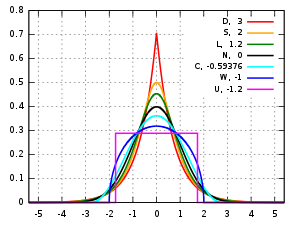
La figure suivante représente quelques distributions à densité unimodales centrées réduites symétriques (, et ).



| Loi de probabilité | Kurtosis normalisé | Symbole dans la figure | Couleur dans la figure |
|---|---|---|---|
| Loi de Laplace | 3 | D | Courbe rouge |
| Loi sécante hyperbolique | 2 | S | Courbe orange |
| Loi logistique | 1,2 | L | Courbe verte |
| Loi normale | 0 | N | Courbe noire |
| Loi du cosinus surélevé | -0,593762… | C | Courbe cyan |
| Loi triangulaire | -0,6 | ||
| Loi du demi-cercle | -1 | W | Courbe bleue |
| Loi uniforme continue | -1,2 | U | Courbe magenta |
Estimateur non biaisé
Une utilisation naïve des définitions théoriques et du coefficient d’aplatissement entraîne des mesures biaisées. Plusieurs logiciels de statistiques (SAS, Tanagra, Minitab, PSPP/SPSS et Excel par exemple, mais pas BMDP (it)) utilisent un estimateur non biaisé pour la loi normale du kurtosis normalisé[4] :

où , et sont des estimateurs non biaisés respectivement de l’espérance, de la variance et du moment d'ordre 4 de la variable étudiée.



Voir aussi
Sur les autres projets Wikimedia :
- Kurtosis, sur Wikimedia Commons
Notes et références
- ↑ Geneviève Coudé-Gaussen, Les poussières sahariennes, John Libbey Eurotext, , 485 p. (ISBN 978-0-86196-304-1, lire en ligne), p. 471.
- ↑ Voir Cumulant (statistiques)#Cumulants et moments.
- ↑ Régis Bourbonnais et Michel Terraza, Analyse des séries temporelles, 2e édition, Dunod, 2008, p. 296.
- ↑ (en) D.N. Joanes et C.A. Gill, « Comparing Measures of Sample Skewness and Kurtosis », Journal of Statistical Societyt. Séries D (The statisticain), vol. 47, no 1, , p. 183-189, page184.
Articles connexes
- Espérance mathématique
- Variance
- Écart type
- Coefficient d’asymétrie
- Approximation de Cornish-Fisher

 Portail des probabilités et de la statistique
Portail des probabilités et de la statistique






