Information retrieval
Information retrieval (IR) houdt zich bezig met het zoeken naar informatie in documenten, naar documenten zelf en naar metadata die de documenten beschrijven, alsook naar het zoeken binnen databases naar tekst, audio, beelden of data. De termen data retrieval, document retrieval, information retrieval en text retrieval worden vaak door elkaar gebruikt, hoewel ze elk over eigen literatuur, theorie, praktijk en technologieën beschikken.
De term "information retrieval" is afkomstig van Calvin Mooers in 1948-50.
Modellen
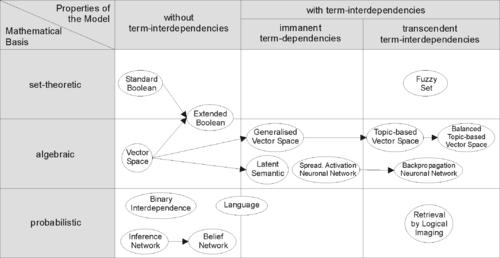
In de information retrieval worden verschillende (wiskundige) modellen gebruikt om documenten en query's te representeren. De basismodellen zijn het booleaanse, het probabilistische en het vectorruimtemodel.
Vectorruimtes
In het vectorruimtemodel wordt een verzameling documenten gerepresenteerd als een verzameling vectoren in een hoogdimensionale ruimte, als volgt.

Eerst wordt ieder document in gereduceerd tot een verzameling termen met bijbehorende absolute frequenties. Doorgaans zijn termen de woorden die in het document voorkomen, na verwijdering van veel voorkomende woorden als de, het, voor enz. (de 'stopwoorden'). De resulterende bag of words wordt door toepassing van wegingsfuncties omgezet in een vector in een -dimensionale ruimte, waarbij het totaal aantal termen in alle documenten van is. Hierbij correspondeert elke unieke term met één dimensie van ; de waarde in die dimensie wordt bepaald door weging van de frequentie van . Als een term in een document niet voorkomt, is de waarde in de corresponderende dimensie 0. De query wordt een soortgelijk proces onderworpen met een vector als resultaat.




De weging van termen geschiedt meestal door normalisering t.o.v. de meest frequente term in het document (term frequency, tf) gevolgd door deling door het aantal documenten waarin de term voorkomt (inverse document frequency, idf); deze wegingsmethode wordt tf×idf genoemd. Er bestaan talloze varianten op dit schema en vaak worden documenten en query's iets verschillende formules gebruikt.
Vervolgens kan een query gebruikt worden om de documenten in te rangschikken van meest naar minst relevant door de afstand of hoek (afgeleid uit het inproduct) tussen de vectoren en te meten. De documenten die de kleinste hoek met de vector hebben, worden verondersteld het meest relevant te zijn.



Evaluatie
Metrieken
- Precisie (precision). Precisie is de verhouding tussen het aantal relevante resultaten (documenten, treffers) en het totaal aantal resultaten dat door het systeem is teruggeven.
- waarbij A is het aantal gevonden relevante documenten in de resultatenlijst en B het aantal niet-relevante documenten in de resultatenlijst.

- Vangst (recall). Vangst is de verhouding tussen het aantal relevante gevonden documenten en het totaal aantal relevante documenten dat er mogelijk zijn. Dit laatste is een van tevoren opgesteld 'wensenlijstje', vaak 'ground truth' of 'gouden standaard' genoemd.
- waarbij A is het aantal gevonden relevante resultaten in de resultatenlijst en C het totaal aantal relevante documenten dat er is in de documenten collectie waarin wordt gezocht.

- Fall-out. Het tegenovergestelde van Vangst; de verhouding tussen het aantal irrelevante gevonden documenten en alle irrelevant documenten die er zijn in de collectie:
- waarbij B is het aantal irrelevante documenten in de resultatenlijst en D het totaal aantal irrelevante documenten dat er is in de documenten collectie.

- F-measure. De F-Measure is het gewogen gemiddelde tussen de Precisie en de Vangst.
- waarbij P staat voor Precisie en V voor Vangst.

- Gemiddelde Precisie (Average Precision, AP). De Precisie en Vangst zijn gebaseerd op de hele lijst van gevonden documenten. Simpel gezegd, de Precisies na elk relevante document worden opgeteld en uiteindelijk gedeeld door het totaal aantal relevante documenten, dus:
- waarbij r is de rank (positie van het document in de teruggevonden lijst), N is het totaal aantal gevonden documenten, rel() is een binaire functie (dus 1 voor een relevant document of 0 voor een niet-relevant document), P() is de Precisie voor een gegeven rank, en C het totaal aantal relevante documenten in de documenten collectie.

- Verder heb je nog de Mean Average Precision, die het gemiddelde is van de Gemiddelde Precisies voor elke aparte query.
- Precision at rank
- Mean reciprocal rank
Evaluatieplatforms
In 1992 lanceerde het Amerikaanse Department of Defense, samen met het National Institute of Standards and Technology (NIST), de Text REtrieval Conference (TREC) als onderdeel van het TIPSTER tekstprogramma. Het doel van TREC is het verschaffen van de infrastructuur die nodig is ter ondersteuning van grootschalige evaluaties van tekst-retrieval methodologieën.
In 2000 werd een Europese tegenhanger van TREC opgericht, de Cross-Language Evaluation Forum (CLEF).
Belangrijke information retrieval onderzoeksgroepen
- Center for Intelligent Information Retrieval aan UMASS
- Information Retrieval aan het Language Technologies Institute, Carnegie Mellon University
- Information Retrieval bij Microsoft Research Cambridge
- PSU Intelligent Systems Research Laboratory
- Information Retrieval Laboratory aan het Harbin Institute of Technology, China
- Information and Language Processing Systems aan de Universiteit van Amsterdam
- Information Retrieval Group aan de Université de Neuchâtel
- European CLEF Initiative,voorheen Cross-Language Evaluation Forum
Literatuur
- Christopher D. Manning, Prabhakan Raghavan, Hinrich Schültze (2009). Introduction to Information Retrieval. Cambridge University Press, USA, blz. 544. ISBN 9780521865715. Geraadpleegd op 18 juni 2009.







